
The Crawling-Log in the Onpage projects shows you in real time how your website is being analysed by our crawler. Thanks to this logfile you’ll get exact insights on the crawling status of your project.
In the evaluation “Crawling-Log” the SISTRIX-crawler gives you insights on the current ongoing project-crawling. If your crawling is not active, you’ll see the data from the last crawl.
The first four boxes show you an overview of the most important information. If the crawler is currently active, the information on this page will be updated every second.
- Crawler-Status: Current status of the SISTRIX-crawler for this project. The possible values are:
- Queued: The crawler has been started. It is currently assigned to a free crawl-server. This usually last just a couple of seconds, but it could also last longer for special settings (e.g. very high number of URLs, fixed IP-Address).
- Crawling: The project crawling is currently ongoing. The data on the page are updated automatically every second.
- Parsing: The crawling has ended. Some final evaluations and analyses are still being completed, so that you can use the crawling-data in the project.
- Finished: At the moment the crawler for this project is not running. Click on the green button “Restart Crawler” to start a crawling anytime you want.
- Runtime: Complete runtime of the current crawling from the beginning until the end of the analysis.
- Crawled URLs: Number of crawled URLs. This includes all URLs found by the crawler, as well as HTML pages, redirects, resources and external links.
- URL Limit: Maximal number of URLs which can be crawled in this project. If the SISTRIX-crawler reaches this limit, it will stop the crawling and evaluate the data gathered until that moment. You can increase the URL limit in the project settings.
You can deactivate the crawling at any time in the ‘Onpage > Overview’ section
Statistics
In this table you can find more information about the scope of the current ongoing crawling. The options in detail:
- Crawled URLs (correct HTML): Number of HTML pages found by the crawler that delivered a status code 200.
- Total URLs crawled: Total number of URLs crawled by the crawler in this project. All HTTP-requests are counted here. This number results from the sum of the three following values.
- Total HTML URLs crawled: Number of HTML-pages in this project, which have been found by the crawler. Here we count the number of HTML-documents which are within the project-scope and have the correct HTML data-type.
- Resource URLs crawled: Number of resources which have been crawled. Resources can be images, CSS and JavaScript files which are included on the HTML-page.
- External URLs crawled: Number of external pages which have been crawled. The SISTRIX-crawler can check whether the links on your website are still correct.
- Queued URLs: Number of URLs that the crawler will process, but which have not been crawled still.
- Blocked URLs: Number of URLs that the crawler couldn’t detect. This happens when a URL is blocked by robots.txt. Here we count only the HTML-pages of the project.
- Failed URLs: Number of URLs which return a 400 or 500 Status Code. Here we count only the HTML-pages of the project.
- Indexable URLs: Number of crawled URLs which can be indexed from Google. These URLs are neither blocked by robots.txt, nor prevented from being indexed by the instructions of the page.
- Bytes transfered: Data-volume transfered with this crawling.
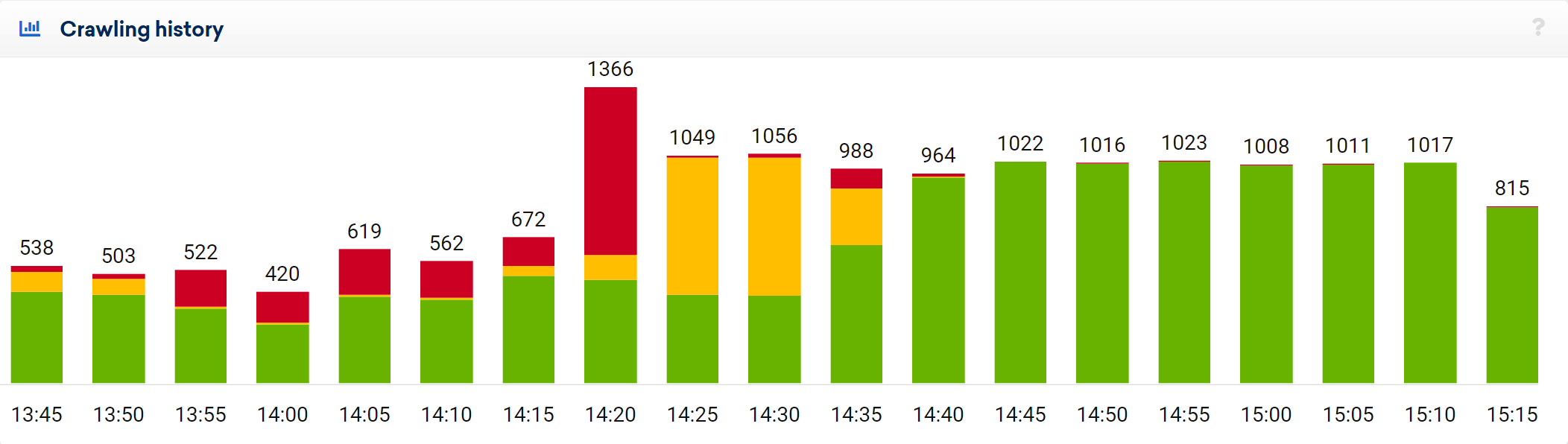
Crawling History
This evaluation shows you the number of crawled URLs every minute. This allows you to see the time history of your crawl at a glance. Pages with a 200 status code are coloured green, redirects (status code 300) yellow and error pages (status code 400 or 500) red.
Crawler Live Logfile
In this table you see the last crawled URLs of your Onpage project. Near the crawling time you can see the status code of the URL, the loadtime in seconds and the actual URL.
After finishing the crawling you can search and sort all URLs inside your project.