
We have fundamentally revised the automated web page checks in the Optimizer: over 100 checks, with additional clarity and usability. You can find out more in this changelog entry.
Working through checklists does not necessarily lead to better rankings, but the Optimizer is always on the lookout for you and it allows you more time to devote to important SEO tasks.
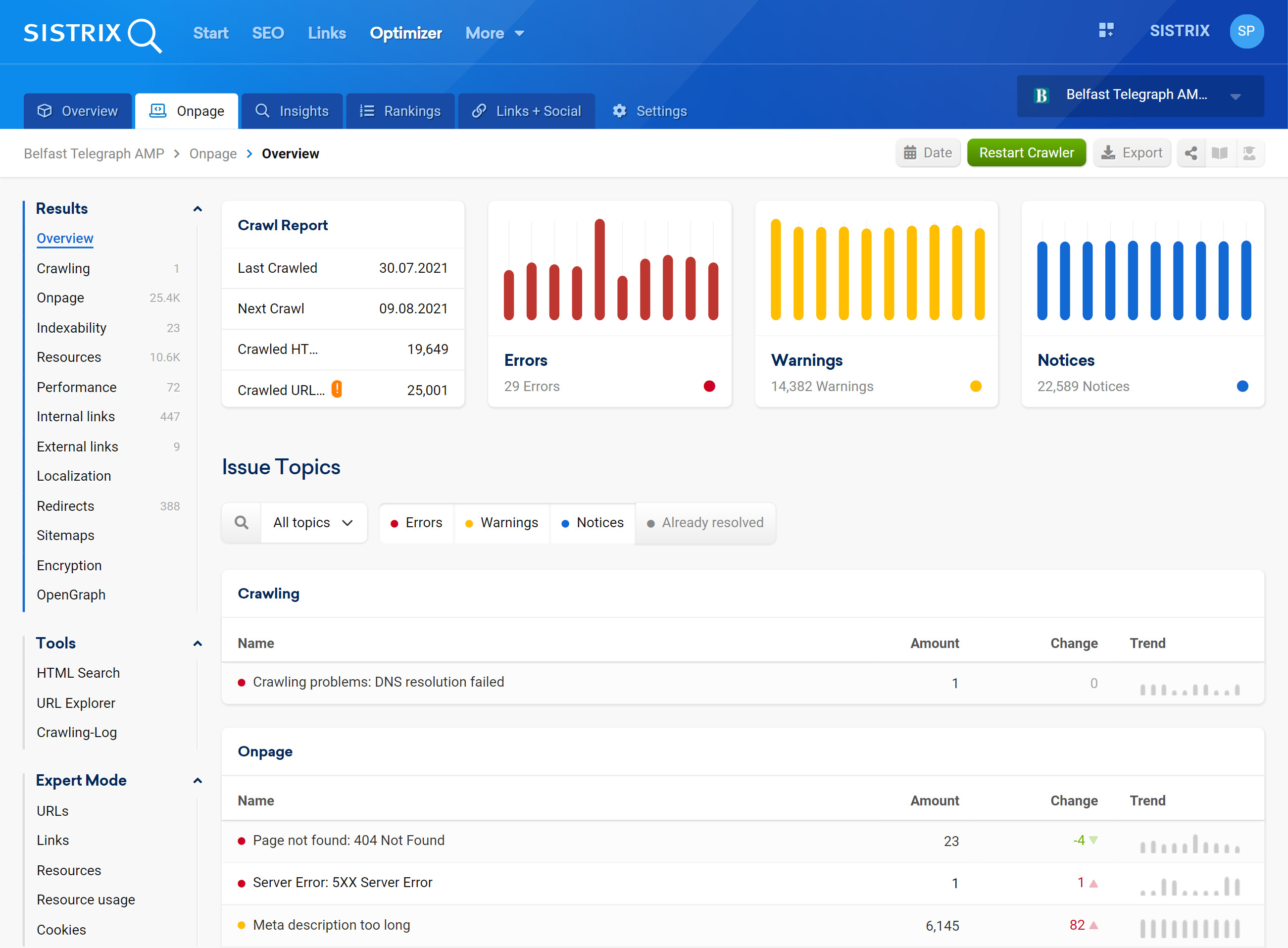
Because of this, we have fundamentally revised, expanded and improved the system of automatic website checks in the Optimizer. Read on for more detail.
More than 100 automatic tests
We’ve added many new checks to the Optimizer which now looks for over 100 different sources of error, completely automatically, with every crawl. In addition to classic SEO topics, the Optimizer now also reminds you, for example, that the domain’s SSL certificate is about to expire or detects errors in the HTML source text of the pages that lead to a parsing error.

Checks now grouped thematically
With so many new checks, we had to bring order to the list of checked items. For this reason, all tests are now sorted by topic. This ranges from classic on-page checks for existing and correct-length titles to link topics to localisation, performance and encryption.
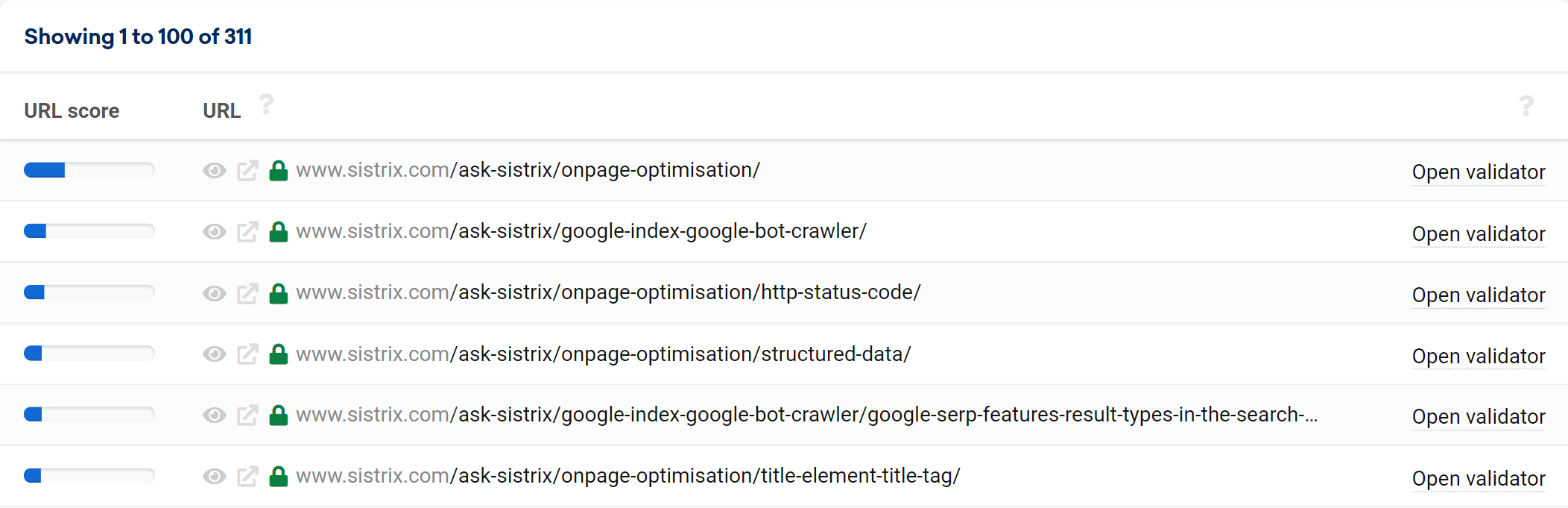
Prioritisation according to URL score
SEO is always about the right prioritisation: differentiating important tasks with major effects from unimportant tasks. The Optimizer will now help you by assigning a URL score to each crawled URL. This works similarly to Google’s PageRank, but only considers internal links – pages that are often linked internally have a high URL score. Pages with few internal links have a low score.
Complete export of all data
The relationships between the data from more than 100 tests are often complex and multidimensional. However, we have found a way to represent data in normal tables within the optimizer. You can filter, sort and easily export all results for further processing with just one click.
Maintains strengths
With all new features and improvements to the on-page checks in the Optimizer, we have made sure to retain our valued strengths. Among other things:
- Chrome-based crawler: the optimizer’s crawler engine is still based on the open source version of Chrome. Since the Googlebot is also based on this, the optimizer behaves exactly like Google in almost all cases.
- Javascript crawling for everyone: crawling Javascript is a significantly more computationally intensive process than pure HTML crawling. Nevertheless, we have decided not to pass these costs on to users. With SISTRIX everyone can scan their website with a Javascript crawler.
- HTML search engine: we keep a complete copy of the (rendered) HTML source code of your website – and you can search this source code at any time. Discover individual errors without having to laboriously configure the crawler.
The changes to the on-page checks in the optimizer have been available to all customers since this week. Depending on the frequency of the automatic crawling, the project may have to be crawled again in order to use all new checks. Have fun!