
Like many search engine optimisers at the beginning of August, I wondered whether Google’s ranking bug (indexing glitch) might be the sign of a new update, or whether the changes in ranking would provide some insights into how optimisation works.
You’ve probably already heard, but for those of you who don’t follow Google’s every step, here’s a summary:
At the beginning of August, there was a massive increase in the fluctuation of search results on Google – worldwide and in all languages. In the Webmaster forums and the usual Black Hat forums, there was immediate speculation about the rollout of a massive unannounced update. The fluctuations and changes within the search result lists were so huge that several major SEO portals in the USA reported the biggest update ever.
In fact, all SEO tools and ranking checkers were suddenly hit with massive shifts within Google’s search results. The search results not only changed; they turned upside down, sometimes with absurd results filling the top positions.
You can see the effects of the bug very clearly in the daily visibility index:
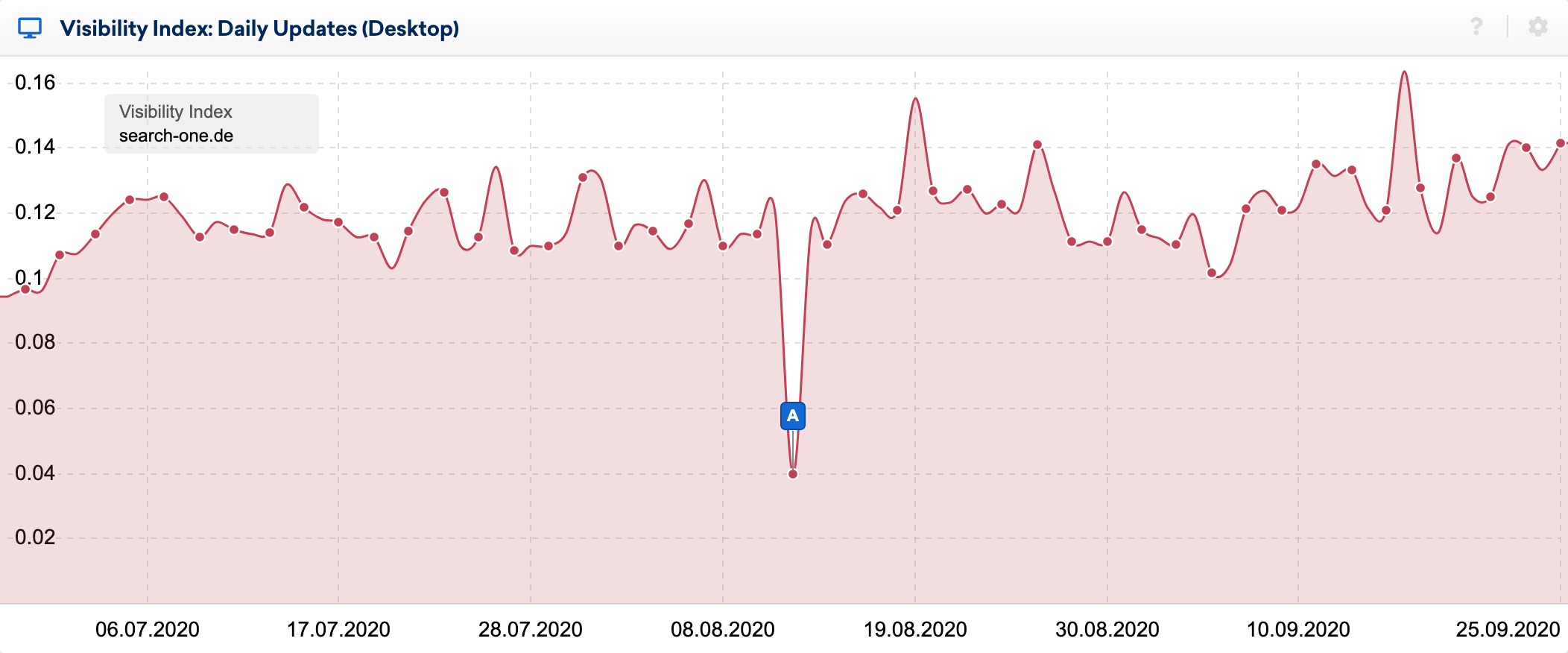
Using the great SERP comparison feature in the SISTRIX toolbox, I took a closer look at the changes within the top 20 of some keywords, whose rankings I have been observing for many years. I’ve done dozens of analyses of the ranked websites for these keywords and usually know relatively well why a URL ranks where it does.
If you take a look at the SERP comparison for the keyword “google optimisation” at the time in question, you will see that the entire top 20, with the exception of one URL, changed completely. What was previously in 1st place moved down to 8th place, with the remaining URLs coming out of nowhere, i.e. from outside the top 20 into the top places.
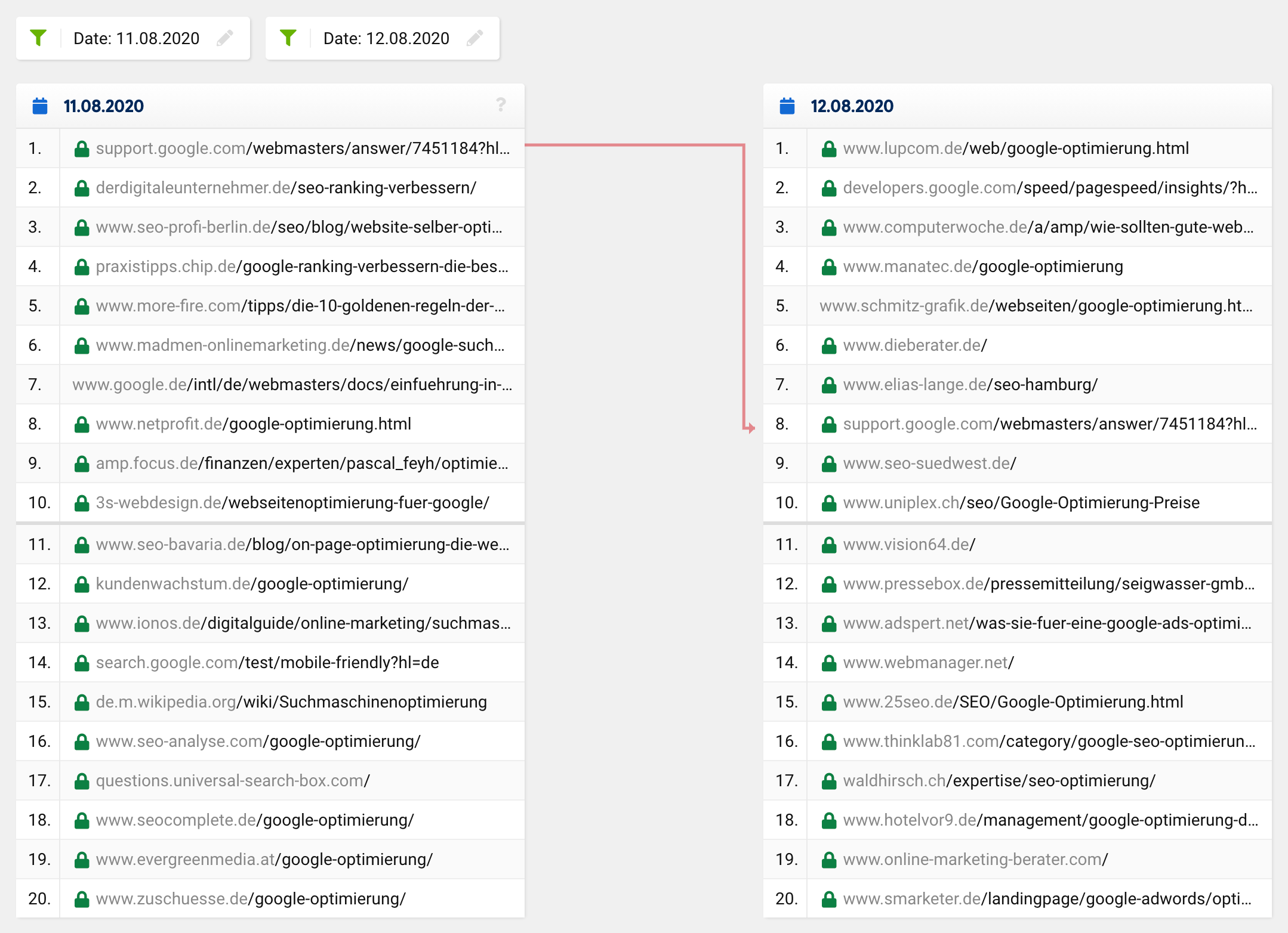
A normal update or a regular ranking change would normally look more like this:

Lots of URLs remain the same, while certain URLs move up and others move down. Of course, sometimes a URL disappears out of the top 20 or moves up into it. However, it is incredibly rare that out of 20 hits, only one is left in the “new” top 20 – this was the case across the board, not just for one specific keyword.
Given such far-reaching changes similar to the notorious phantom updates, you would expect to see an adjustment in the assumed user intent of a search query, which would then lead to fundamental changes in the composition of the top 20 for some keywords. In such a case, however, the search results would improve, i.e. become more relevant and meaningful, which was obviously not what occurred with this glitch.
The vast majority of SEOs were surprised by the obviously absurd search results and relatively quickly assumed that there was an error – or at least hoped that it was just a temporary issue. I felt the same way, as some of my websites completely lost their most important rankings in the space of a few hours!
A nasty surprise: It was just a mistake!
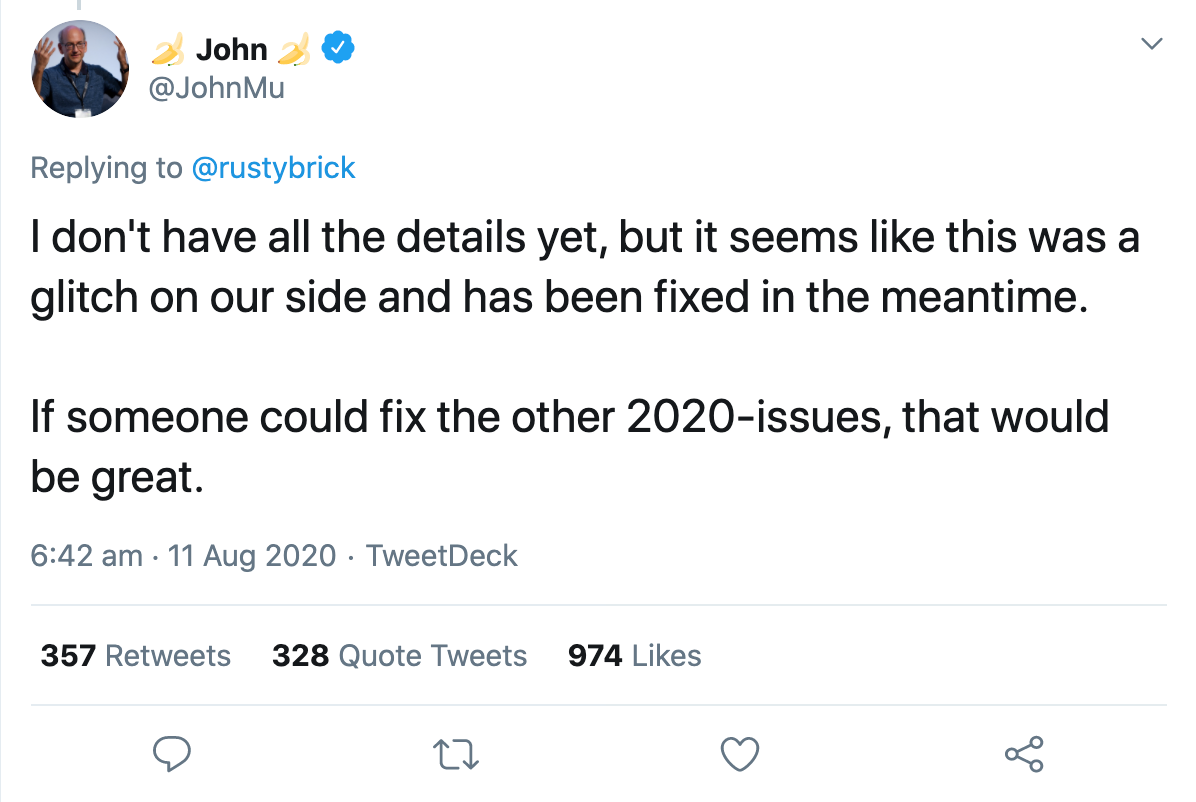
That same night, a Google spokesperson confirmed that it was a bug they were fixing. Within a few hours, everything was back to normal. John Müller confirmed via Twitter that the bug had been fixed, but that he didn’t have all the details yet:
Just one day later, the official Google Webmaster account confirmed that the search results had been affected by an apparent problem with the indexing system.
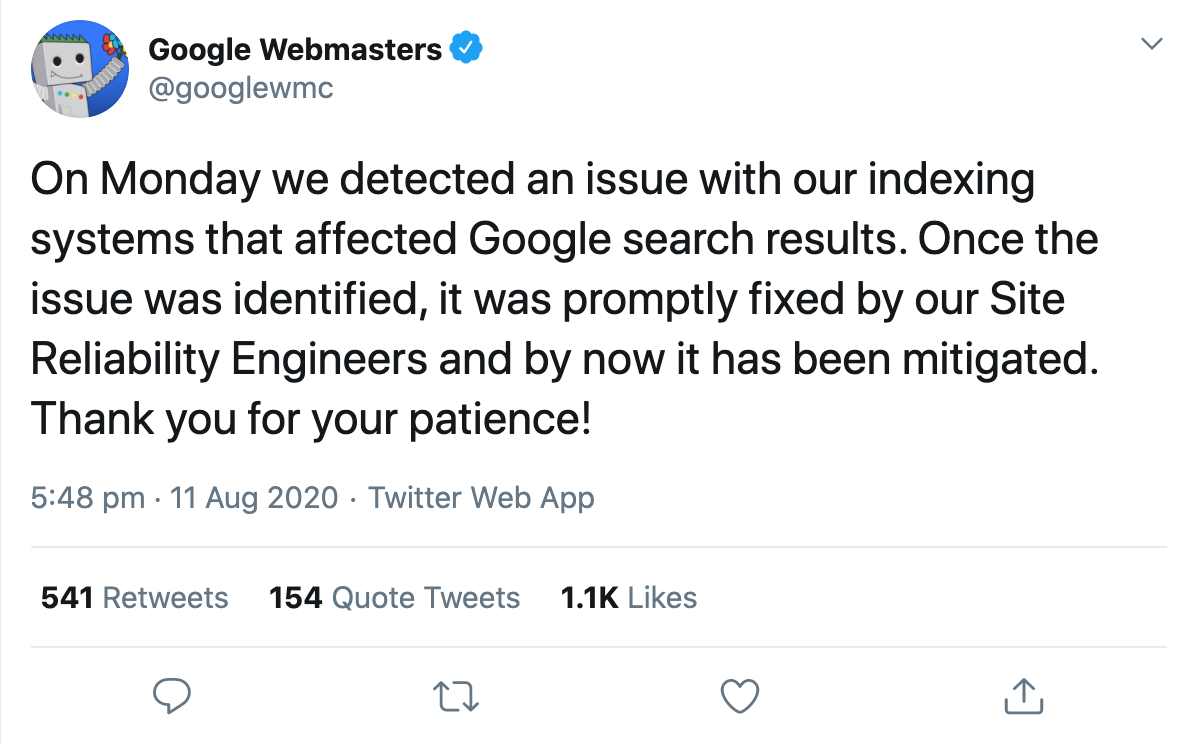
And this is where people began to speculate about what exactly might have happened.
Gary Illyes tried to make things a little more concrete by describing what the indexing system, Caffeine, actually does. According to his tweet, it ingests fetchlogs, renders and converts fetched data, extracts links, meta and structured data, extracts and computes some unnamed signals, schedules new crawls, and builds the index that is pushed to serving. To make this easier to understand, he gave some examples of what could go wrong, which would then be reflected in changed search results:
“If scheduling the crawls goes awry, crawling may slow down. If rendering goes wrong, Google may misunderstand the pages. If index building goes bad, ranking and serving may be affected.”
He then emphasised how complex the search is, and that thousands of interconnected systems must work together flawlessly to deliver relevant results to users. If a grain of sand is thrown in the machinery, the result would be an outage just like yesterday.
When asked by a Twitter user, he specified that there had apparently been an error in the building of the index itself:
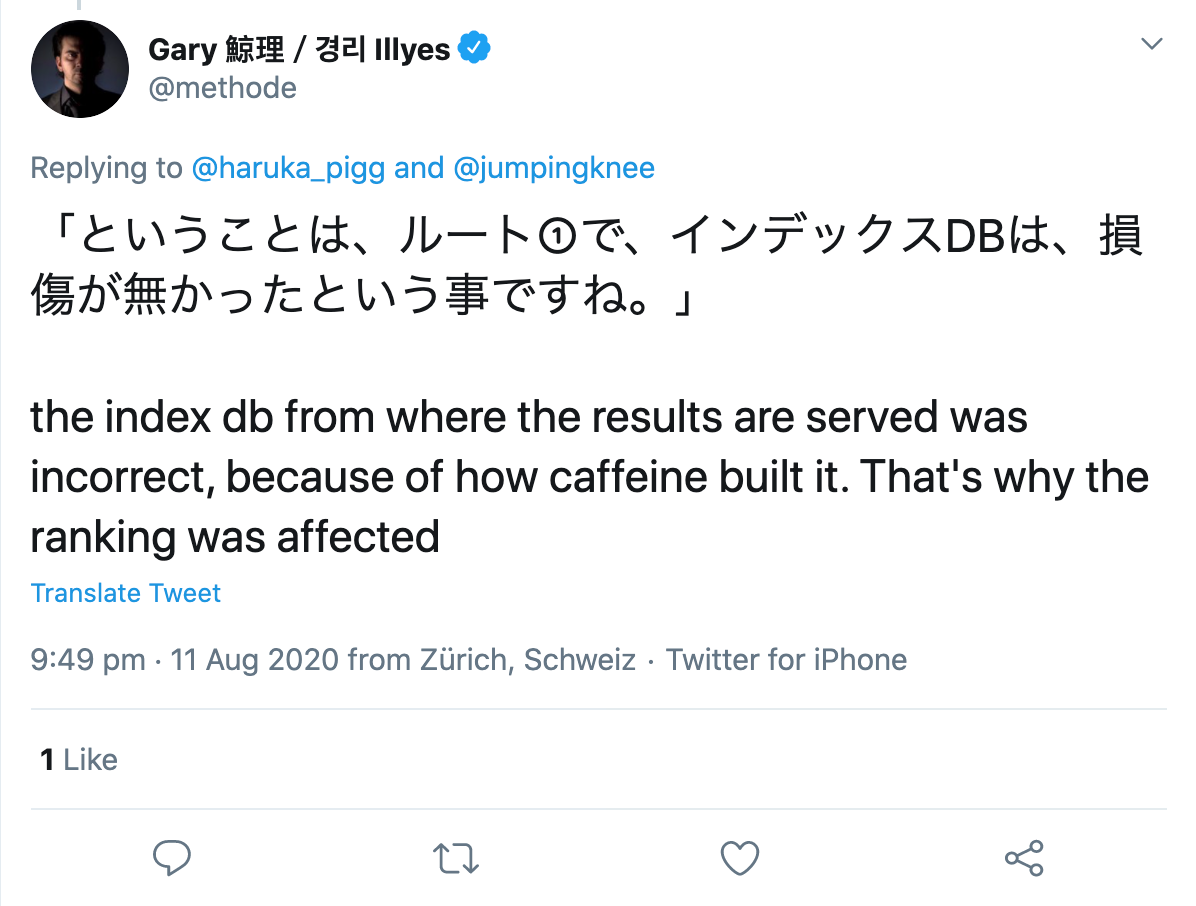
So, where’s the problem in all this?
The bug itself didn’t annoy me, as it was only a matter of hours before Google fixed the issue. However, some comments and publications about it afterwards made me rather angry.
Although Google had disclosed the problem relatively transparently, some SEOs tried to make sense of the bug by hook or by crook and started to examine the changes to look for patterns. An employee of a well-known American SEO agency, whom I don’t want to expose at this point, started to analyse the Google Analytics data of every current and former client and tried to draw conclusions about the reason for the ranking changes.
I consider this to be crossing the line for several reasons, but more about that later.
What did the employee(s) find out about the glitch?
In the case of regular Google updates, all subpages of a domain would usually be affected by the change, whether positive or negative. This was not the case with the current glitch, because while some subpages of one and the same domain suffered massive losses, others profited and some hardly changed, if at all.
Their first insight was therefore that it didn’t look like a typical Google update. So far, so good.
Now it becomes somewhat adventurous:
“Many pages that went higher up the rankings contained medical information that contradicted the scientific consensus. For clarification, reference is made here to the Google Quality Rater Guidelines which state that when determining the E-A-T of a page on scientific topics, it should be created by people or organisations with expertise in the respective field and should reflect the established consensus of science, where one exists.”
This assertion is “proven” by the observation that a few medical articles, which obviously contradict the state of science and also have bad or unnatural backlinks, suddenly ranked much better than before and after the bug.
Their theory is that pages that should be devalued because of quality problems actually ranked well. For example, hacked pages, pages with unnatural links or pages with claims that deviate from the general scientific consensus would have been catapulted into top positions.
From this, the author deduces the following:
If the rankings of a page improve, this could be a reason for rejoicing, or maybe it was just
a test for a future update that went wrong. Or it could be an indication of a quality problem with the website, which limited the ranking of the page, but might not have played a role at the time of the bug.
On the other hand, if a page had moved down the rankings, this could mean you were overtaken by inferior or spammy pages, which are once again currently downgraded by Google’s algorithms.
Uffz! Really? What good is this insight for my daily SEO work?!
Why not perform such analyses?
Apart from the fact that they still have access to and use the Google Analytics data of former clients, I see a much bigger problem here with the employee’s approach:
The problem is that if you look for patterns without a hypothesis, you will always find something. If you then take that result, without further testing, as being correct, it has nothing to do with science.
There are always patterns, sometimes random, sometimes caused by one or more factors. You cannot search for patterns first and then devise a theory to explain what you observe and, following that, take it as reality. That’s just not how knowledge works.
I would really like to see more scientific methods being used in SEO, for example when it comes to making hypotheses and then testing them!
What is a hypothesis and how do you formulate one correctly?
A hypothesis is a reasonable assumption that is made at the beginning of an empirical study. This assumption is analysed using qualitative or quantitative methods and is then confirmed or disproved.
When making a hypothesis, you either assume a correlation or no correlation between two variables. An independent variable is the cause, the dependent variable is the possible effect.
There are essentially two types of hypotheses: directed and undirected.
With an undirected hypothesis, you merely assume there is some correlation between two variables. For example, the number of linked websites influences the visibility of a domain.
With a directed hypothesis, on the other hand, the presumed correlation is evaluated. For example: the more backlinks an article has, the better it ranks.
However, in order to make a hypothesis, you should consider the following criteria:
- Both the variables used must be measurable.
- Hypotheses must be formulated objectively and concisely.
- If several hypotheses are formulated, they must not contradict each other.
- And: Scientific assumptions must be able to be refuted.
Since most of the assumptions in the field of SEO cannot be disproved by an experiment, there is no evidence to speak of from a scientific perspective. Likewise, you should not analyse the results of any search queries in order to draw conclusions about the ranking factors used.
The realisation that correlation does not equal causality has fortunately become accepted in recent years. Studies on the ranking factors of any tool provider are no longer taken seriously by any experienced SEO today, which means that fewer and fewer of them are carried out and published.
